
This article explains the implementation of Macro-averages and Weighted Macro-averages as explained in this post and this Data Science post. Specifically, we add macro-averages and weighted macro-averages precision metrics into the lesson 3 of Practical Deep Learning for Coders, v3.
Lesson 3 describes how to deal with image segmentation problem, that is predicting a category for each pixel in an image. The image dataset comes from CamVid dataset.
In order to run the codes below, you need to install the fastai library.
Let’s start by importing all the required libraries.
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.vision import *
from fastai.callbacks.hooks import *
from fastai.utils.mem import *
We untar the CamVid dataset.
path = untar_data(URLs.CAMVID)
path.ls()
Out:
[PosixPath('/home/jupyter/.fastai/data/camvid/codes.txt'),
PosixPath('/home/jupyter/.fastai/data/camvid/labels'),
PosixPath('/home/jupyter/.fastai/data/camvid/valid.txt'),
PosixPath('/home/jupyter/.fastai/data/camvid/images')]
We create a path to the labels and all images.
path_lbl = path/'labels'
path_img = path/'images'
Let’s get the images.
fnames = get_image_files(path_img)
fnames[:3]
Out:
[PosixPath('/home/jupyter/.fastai/data/camvid/images/0001TP_008730.png'),
PosixPath('/home/jupyter/.fastai/data/camvid/images/Seq05VD_f00090.png'),
PosixPath('/home/jupyter/.fastai/data/camvid/images/0006R0_f03570.png')]
Let’s show some image labels.
lbl_names = get_image_files(path_lbl)
lbl_names[:3]
Out:
[PosixPath('/home/jupyter/.fastai/data/camvid/labels/0016E5_08067_P.png'),
PosixPath('/home/jupyter/.fastai/data/camvid/labels/Seq05VD_f03870_P.png'),
PosixPath('/home/jupyter/.fastai/data/camvid/labels/0016E5_01200_P.png')]
Let’s show one image.
img_f = fnames[0]
img = open_image(img_f)
img.show(figsize=(5,5))
Out:

Next, we create a method to open a mask and show the mask.
get_y_fn = lambda x: path_lbl/f'{x.stem}_P{x.suffix}'
mask = open_mask(get_y_fn(img_f))
mask.show(figsize=(5,5), alpha=1)
Out:

Let’s view the mask data.
src_size = np.array(mask.shape[1:])
src_size,mask.data
Out:
(array([720, 960]),
tensor([[[26, 26, 26, ..., 4, 4, 4],
[26, 26, 26, ..., 4, 4, 4],
[26, 26, 26, ..., 4, 4, 4],
...,
[17, 17, 17, ..., 30, 30, 30],
[17, 17, 17, ..., 30, 30, 30],
[17, 17, 17, ..., 30, 30, 30]]]))
Particularly, the categories for each pixel are shown in code below.
codes = np.loadtxt(path/'codes.txt', dtype=str); codes
Out:
array(['Animal', 'Archway', 'Bicyclist', 'Bridge', 'Building', 'Car', 'CartLuggagePram', 'Child', 'Column_Pole',
'Fence', 'LaneMkgsDriv', 'LaneMkgsNonDriv', 'Misc_Text', 'MotorcycleScooter', 'OtherMoving', 'ParkingBlock',
'Pedestrian', 'Road', 'RoadShoulder', 'Sidewalk', 'SignSymbol', 'Sky', 'SUVPickupTruck', 'TrafficCone',
'TrafficLight', 'Train', 'Tree', 'Truck_Bus', 'Tunnel', 'VegetationMisc', 'Void', 'Wall'], dtype='<U17')
Next, we use the appropriate batch size depending on the free GPU RAM.
size = src_size//2
free = gpu_mem_get_free_no_cache()
# the max size of bs depends on the available GPU RAM
if free > 8200: bs=8
else: bs=4
print(f"using bs={bs}, have {free}MB of GPU RAM free")
Out:
using bs=8, have 15068MB of GPU RAM free
Let’s create our data with the reduced size (src_size//2) images and get_transforms() transformations. Please check the default get_transforms() transformation in this documentation.
data = (src.transform(get_transforms(), size=size, tfm_y=True)
.databunch(bs=bs)
.normalize(imagenet_stats))
We show several train images with both images and the labels.
data.show_batch(2, figsize=(10,7))
Out:

We show several validation images with both images and the labels.
data.show_batch(2, figsize=(10,7), ds_type=DatasetType.Valid)
Out:

There is Void category in CamVid dataset and this category should be removed according to the paper. Additionally, we also define the accuracy for CamVid dataset.
name2id = {v:k for k,v in enumerate(codes)}
void_code = name2id['Void']
def acc_camvid(input, target):
target = target.squeeze(1)
mask = target != void_code
return (input.argmax(dim=1)[mask]==target[mask]).float().mean()
Since we remove Void category, the categories shall be reduced to 31 from previously 32.
new_classes = []
for value in name2id.values():
if value != name2id['Void']:
new_classes.append(value)
print(f"Before: {len(name2id.values())}, After: {len(new_classes)}")
Out:
Before: 32, After: 31
Next, we define macro-averages precision and weighted macro-averages precision for the CamVid dataset.
def macro_avg_prec_camvid(input, target):
# tp = torch.sum( ( input.argmax(dim=1)[mask] == 1) & (target[mask] == 1 ) )
# fp = torch.sum( ( input.argmax(dim=1)[mask] == 1) & (target[mask] == 0 ) )
# ================================================================
# Beware that we need 'new_classes' from outside the function
# ================================================================
tensor_tp = torch.zeros(data.c)
tensor_fp = torch.zeros(data.c)
target = target.squeeze(1)
mask = target != void_code
for indeks in new_classes:
tp = torch.sum( ( input.argmax(dim=1)[mask] == indeks) & (target[mask] == indeks ) )
fp = torch.sum( ( input.argmax(dim=1)[mask] == indeks) & (target[mask] != indeks ) )
tensor_tp[indeks] = tp
tensor_fp[indeks] = fp
tensor_prec = tensor_tp / ( tensor_tp + tensor_fp)
tensor_prec[tensor_prec != tensor_prec] = 0
return (tensor_prec.sum()) / len(new_classes)
def weighted_macro_avg_prec_camvid(input, target):
# tp = torch.sum( ( input.argmax(dim=1)[mask] == 1) & (target[mask] == 1 ) )
# fp = torch.sum( ( input.argmax(dim=1)[mask] == 1) & (target[mask] == 0 ) )
# ================================================================
# Beware that we need 'new_classes' from outside the function
# ================================================================
tensor_tp = torch.zeros(data.c)
tensor_fp = torch.zeros(data.c)
target = target.squeeze(1)
mask = target != void_code
for indeks in new_classes:
tp = torch.sum( ( input.argmax(dim=1)[mask] == indeks) & (target[mask] == indeks ) )
fp = torch.sum( ( input.argmax(dim=1)[mask] == indeks) & (target[mask] != indeks ) )
tensor_tp[indeks] = tp
tensor_fp[indeks] = fp
tensor_prec = tensor_tp / ( tensor_tp + tensor_fp)
tensor_prec[tensor_prec != tensor_prec] = 0
tensor_prec = tensor_prec * (tensor_tp + tensor_fp) / torch.sum(tensor_tp + tensor_fp)
return tensor_prec.sum()
Let’s put all the metrics together and define weight decay (wd).
metrics=[acc_camvid, macro_avg_prec_camvid, weighted_macro_avg_prec_camvid]
wd=1e-2
We create an instance of unet_learner with resnet34 model, metrics, and wd.
learn = unet_learner(data, models.resnet34, metrics=metrics, wd=wd)
Let’s utilize learning rate finder based on the paper.
lr_find(learn)
learn.recorder.plot()
Out:
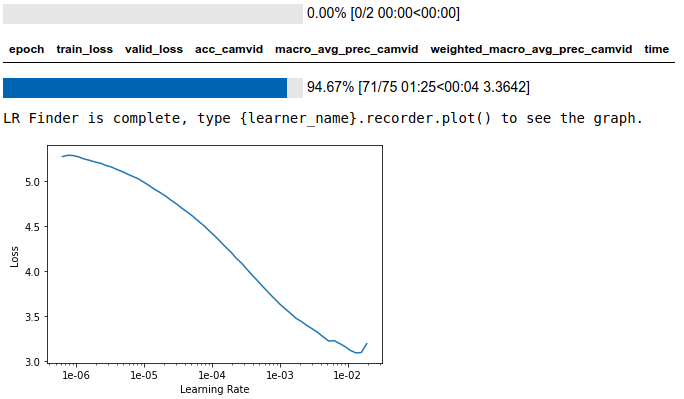
We opt to choose a value before the steepest plot happens, for example, we choose the following learning rate:
lr=3e-3
Next, we execute the one cycle with the chosen learning rate.
learn.fit_one_cycle(4, slice(lr), pct_start=0.9)
Out:

We save the first stage of our model.
learn.save('stage-1-with-prec')
Finally, we have shown how to implement macro-averages precision and weighted macro-averages precision for the CamVid dataset. This article only explains the precision.
An Exercise for You to Try:
You can also implement macro-averages recall, weighted macro-averages recall, and macro-averages \(\pmb{F}_1\) score, weighted macro-averages \(\pmb{F}_1\) score.
PS:
If you do not need to modify the categories in your dataset, you can directly employ ready-to-use metrics classes such as Precision, Recall, and FBeta.